

Chi tiết về Xe-LP – Tiến trình SuperFin sẽ chắp cánh hiệu năng
Chi tiết về Xe-LP – kiến trúc GPU cốt lõi của Intel, tiến trình SuperFin sẽ chắp cánh hiệu năng
Chiếm một phần lớn diện tích của Tiger Lake là Xe-LP với nhiều cải tiến về kiến trúc. Tiến trình 10nm SuperFin cũng hứa hẹn sẽ đưa hiệu năng/điện năng của Xe-LP lên cao hơn nữa, từ đó khiến những con SoC Tiger Lake trở nên hấp dẫn hơn rất nhiều. Ngoài ra, Xe còn là kiến trúc có thể tăng tỉ lệ và qua đây chúng ta cũng có thể phần nào hình dung được hiệu năng của Xe-HPG – card đồ họa dành cho game thủ đầu tiên của Intel.
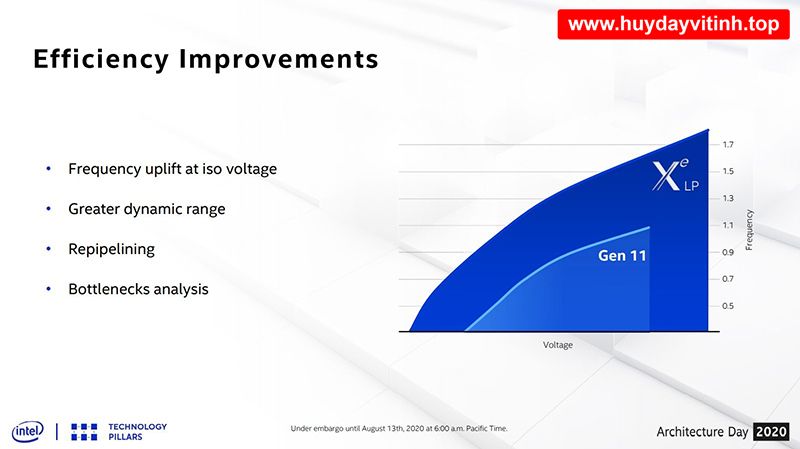
SuperFin kết hợp nhiều sáng kiến nhằm hoàn thiện tiến trình 10nm của Intel để khiến những con Tiger Lake đạt được xung cao hơn và GPU tích hợp Xe-LP cũng được hưởng lợi từ tiến trình này. Theo biểu đồ trên thì cùng một mức điện áp, Xe-LP sẽ có thể đạt được mức xung gần 1650 Mhz và tối đa đến 1800 MHz ở điện áp cao hơn trong khi Iris Plus trên Ice Lake chỉ có thể đạt 1100 MHz – một mức xung phổ biến của GPU tích hợp trên vi xử lý Intel xưa nay.
Intel muốn xây dựng Xe-LP là một nền tảng xử lý đồ họa chuẩn để các sản phẩm về sau có thể phát triển dựa trên nó. Vậy nên nhân Xe-LP được tổ chức thành các slice, mỗi slice sẽ bao gồm một cụm nhiều block nhân đầy đủ chức năng để có thể thực hiện hoạt động tính toán và kết xuất. Mỗi slice có các đơn vị xử lý hình học và raster ở frontend, có phần cứng quản lý đơn luồng, có các EU, đơn vị xử lý bề mặt TMU và ROP ở backend.

Với Xe-LP, Intel đã mở rộng mỗi slice lên 50% tức là bên trong mỗi slice sẽ có thêm 50% EU, thêm 50% TMU, thêm 50% ROP … so với Gen11 trên Ice Lake. Như vậy Xe-LP có thêm 32 EU thành 96 EU với 768 ALU xử lý FP/Integer so với 64 EU tối đa của Gen11, có 48 TMU cho tổng cộng 48 texel/lock, có 24 ROP cho tổng cộng 24 pixel/clock. Intel cũng cải tiến đơn vị hình học để tăng gấp đôi hiệu năng đồ họa hình học để đạt được tỉ lệ trên 1 tam giác/chu kỳ xung – một điều không đơn giản bởi theo định nghĩa, một GPU với khả năng dựng trên 2 hình tam giác/chu kỳ xung sẽ có thể dựng được nhiều hình tam giác cùng lúc bằng cách chuyển đổi tiến trình chuỗi thành tiến trình song song. Chẳng hạn như GPU của Xbox One X hay PS4 có thể dựng 2 hình tam giác/chu kỳ xung còn GPU Radeon dùng kiến trúc RDNA của AMD có thể dựng 4 hình tam giác/chu kỳ xung.
Cùng với xung nhịp rất cao thì hiệu năng FP32 của Xe-LP có thể đạt đến 2,46 TFLOPS, Iris Plus bản 64 EU hiện tại chỉ đạt 1,13 TFLOPS còn UHD Graphics dùng kiến trúc đồ họa Gen9.5 như trên dòng Kaby Lake chỉ cho 0,44 TFLOPS.

Một cải tiến nữa nằm ở tổ chức các subslice bên trong một slice chính. Nếu như GPU Gen11 trên Ice Lake được chia thành 8 subslice thì Xe-LP được tái tổ chức để giảm số lượng subslice xuống còn 6. Subslice này cũng tương đương như cụm SM (Streaming Multiprocessor) của Nvidia và đối với từng dòng GPU, Nvidia sẽ tắt bớt SM để phân chia phân khúc và việc tắt bớt SM sẽ dẫn đến sự khác biệt về số nhân CUDA, số nhân RT hay Tensor như chúng ta thấy trên dòng Turing hiện tại. Mỗi subslice sẽ có 16 EU (96 chia 6) nhưng điều đáng chú ý là chúng có bộ đệm L1 cho data/texture riêng với độ lớn là 64 KB và có thể được phân bổ linh hoạt tức có thể chứa data hoặc texture.

Xuống đến nhỏ hơn với EU: Trước tiên hãy nhìn lại Gen11 trên Ice Lake. Một EU của GPU Gen11 bao gồm một đơn vị kiểm soát luồng (Thread Control) và một 2 nhóm SIMD (single instruction, multiple data) chứa các ALU (đơn vị logic số học – Arithmetic Logic Unit), độ rộng là 4 luồng (4 thread) mỗi SIMD (gọi là SIMD4). Một SIMD sẽ có chức năng tính toán dấu chấm động (FP) và tính toán số nguyên (integer) trong khi SIMD còn lại ngoài tính toán FP thì sẽ kiêm tính toán một số phép tính đặc biệt mà Intel gọi là các phép tính mở rộng (Extended Math – EM).

Mặc dù vậy, độ rộng wavefront nhỏ nhất của GPU Gen11 là 8 thread (SIMD8) nên để thực thi một wavefront đơn lẻ thì nó sẽ cần nhiều chu kỳ xung hơn (bởi động rộng SIMD là 4 thread, chỉ bằng 1/2 độ rộng wavefront) và từ đó tạo ra độ trễ. Đây là điều mà AMD cũng đã gặp phải trên kiến trúc GCN5 của Vega và trên RDNA thì hãng đã cải tiến bằng cách tăng độ rộng của SIMD từ 16 lên 32 để khớp hoàn toàn với độ rộng của wavefront là 32 từ đó giảm tối đa độ trễ khiến RDNA cho hiệu năng cao hơn nhiều so với GCN. Thiết kế 2 cụm SIMD4 tạo ra 1 SIMD8 nhưng số ALU thì vẫn không đổi, vẫn 8 ALU trên mỗi EU và việc tính toán EM vẫn được đảm nhiệm bởi 4 ALU dùng xen lẫn chức năng tính toán FP và EM.

Trên Xe-LP, Intel làm điều tương tự nhưng có phần khéo léo hơn, đầu tiên là 1 EU sẽ không còn là một khối độc lập mà thay vào đó 2 EU dùng chung một đơn vị kiểm soát đơn luồng. Kết quả là bộ điều khiển này sẽ có thể chia việc cho 2 EU cùng lúc thay vì 1 và các khối SIMD được tổ chức lại. Không còn là 2 nhóm SIMD4 thực hiện các chức năng khác nhau mà chúng được chia thành SIMD8 + SIMD2 trong đó nhóm SIMD8 với độ rộng 8 thread sẽ xử lý FP và Integer còn SIMD2 với độ rộng 2 thread dành riêng cho EM. Như vậy theo sơ đồ trên thì SIMD2 với 2 ALU dành cho EM được tách riêng ra, nó không còn nằm chung với nhóm SIMD8 với 8 ALU dùng để xử lý FP và Integer nữa.

Kết quả là EU có thể đồng thời đưa ra các chỉ thị cho nhóm SIMD8 xử lý FP và Integer cũng như SIMD2 xử lý EM, số ALU dành cho FP/Integer vẫn được giữ nguyên là 8. Có thể thấy Intel đã ít nhiều “bắt chước” cách thiết kế GPU của AMD và Nvidia với Xe-LP và việc thiết kế SIMD8 dành cho FP/Integer tách riêng đã khiến độ rộng của khối SIMD này bằng với độ rộng tối thiểu của wavefront là 8 thread > không cần đến nhiều chu kỳ xung để thực hiện một chỉ thị > hạn chế độ trễ. Xe-LP cũng sẽ hỗ trợ wavefront 16 và 32 như các GPU hiện tại nhưng nếu sử dụng wavefront lớn thì SIMD8 vẫn cần nhiều chu kỳ để xử lý, chí ít là với thế hệ Xe đầu tiên.

Một điểm mới nữa là Xe-LP có bộ đệm L1 dành cho data và texture cho mỗi subslice với dung lượng 64 KB. Thêm vào đó, GPU Xe-LP cón thể đi với đệm L3 dành riêng dung lượng tối đa đến 16 MB so với 3 MB của Gen11. Trên Tiger Lake thì bộ đệm L3 dành riêng cho Xe-LP là 3,8 MB nhưng nếu Xe-LP xuất hiện dưới dạng card đồ họa rời chẳng hạn như DG1 hoặc là một giải pháp GPU rời nằm tách biệt với CPU thì nó sẽ có thể được trang bị đến 16 MB L3.

Không chỉ bộ đệm dung lượng lớn hơn, tốc độ truy xuất bộ đệm L3 của Xe-LP cũng nhanh hơn so với bộ đệm L3 trên Gen11 bởi Intel đã tăng gấp đôi tỉ lệ truyền tải với 128 byte/chu kỳ xung và như vậy nếu xung nhịp của GPU là 1,6 GHz thì băng thông của L3 sẽ có thể đạt 190 GB/s. Intel từng nhấn mạnh về việc phải tăng băng thông ra sao để đáp ứng nhu cầu trao đổi dữ liệu lớn hơn với các thành phần mới trên GPU từ đó thực hiện mục tiêu tăng gấp đôi hiệu năng của GPU. Ngoài ra trên Tiger Lake thì ring bus đã được cải tiến thành dual ring bus và việc tăng tốc độ truy xuất cùng băng thông cũng là nhằm đáp ứng cho kiến trúc ring bus mới này.

Việc sử dụng dual ring bus tạo ra một vòng lặp thứ 2 kết nối 4 nhân của CPU với Xe-LP cũng như vi điều khiển bộ nhớ DRAM tích hợp (IMC). Lợi thế của thiết kế này đó là tăng gấp đôi băng thông giữa GPU và IMC từ đó mỗi chu kỳ xung dual ring bus sẽ có thể gởi gấp đôi lượng dữ liệu tức 128 byte/chu kỳ xung qua 2 giao thức đồ họa (Graphics Technology Interface – GTI).

Để tối ưu hóa mọi thứ thì tốc độ của ring bus sẽ phải khớp với tốc độ bộ nhớ hệ thống mà Tiger Lake hỗ trợ, ở đây là LPDDR5-5200. Intel không nói về điều này nhưng 1 điều tương tự mà chúng ta đã thấy về vai trò của tốc độ cầu kết nối cần phải khớp với tốc độ bộ nhớ đó là cầu Infinity Fabric trên Ryzen của AMD – 1800 MHz tối ưu tốt nhất với DDR4-3600 để đạt tỉ lệ 1:1.

Như vậy với việc bố trí 8 ALU cho FP/Integer thì hiệu năng FP32 và FP16 của Xe-LP và Gen11 vẫn tương đương nhau lần lượt là 16 ops/chu kỳ xung và 32 ops/chu kỳ xung nhưng về hiệu năng xử lý Integer, do không bị mất 4 ALU cho cụm SIMD4 để xử lý EM như Gen11 mà vẫn đủ 8 ALU thành ra hiệu năng xử lý Integer của Xe-LP sẽ gấp đôi so với Gen11 tức INT32 là 8 ops/chu kỳ xung và INT16 là 32 ops/chu kỳ xung. Một điểm đặc biệt là với Xe-LP, Intel hỗ trợ tính toán INT8 – phép tính phổ biến trong lĩnh vực trí thông minh nhân tạo từ đó tăng hiệu năng xử lý các tác vụ có ứng dụng AI. Với tập chỉ thị DP4A thì hiệu năng INT8 sẽ đạt 64 ops/chu kỳ xung.

Ngoài ra, Xe-LP trên Tiger Lake cũng sẽ hỗ trợ giải mã AV1 và Intel cũng đã tăng gấp đôi thông lượng mã hóa/giải mã đối với các codec phổ biến. Điều này có nghĩa Xe-LP trên Tiger Lake cũng sẽ hỗ trợ hoàn toàn video 12-bit HDR và phát video 8K ở tốc độ 60 frame.

Ngoài ra GPU này cũng mở rộng hỗ trợ trình xuất tối đa 4 màn hình 4K, xuất đồng thời qua các cổng DisplayPort 1.4, HDMI 2.0, Thunderbolt 4 và USB4. Thêm vào đó nó còn mặc định hỗ trợ Adaptive Sync và màn hình với tốc độ làm tươi đến 360 Hz.
Một khía cạnh được Intel nhắc đến nhiều của kiến trúc Xe là Scalable – khả năng tăng tỉ lệ mà ở đây ám chỉ 1 kiến trúc nhiều nền tảng. Xe-LP trên Tiger Lake là phiên bản Xe nhỏ nhất, là giải pháp tích hợp và GPU giá rẻ. Intel sẽ hướng Xe đến nhiều thị trường khác nhau gồm Xe-HPC: dành cho các ứng dụng tính toán hiệu năng cao, Xe-HP dành cho trung tâm dữ liệu và AI, Xe-HPG là dòng card đồ họa dành cho game thủ cũng như giải pháp đồ họa tầm trung.

Trước tiên là Xe-HPG – dòng Xe mà chúng ta sẽ có thể tiếp cận sớm nhất khi nó hướng đến đối tượng game thủ. Xe-HPG sẽ hỗ trợ bộ nhớ GDDR6 – dòng bộ nhớ tốc độ cao, cho băng thông đủ lớn để đáp ứng các tác vụ đồ họa hiệu năng cao như game với chi phí thấp hơn so với HBM. Dòng Xe-HPG cũng sẽ có phần cứng dành riêng cho Ray Tracing.

Trong khi đó Xe-HP và HPC sẽ lần lượt hướng đến các trung tâm dữ liệu và tính toán hiệu năng cao. Những GPU này sẽ chứa hàng trăm hay hàng ngàn EU Xe-LP, xung nhịp tối đa và đi với bộ nhớ HBM để tối ưu về khía cạnh dung lượng, băng thông từ đó cho hiệu năng tính toán FP tốt nhất. Dòng Xe-HP có 3 tile tương ứng với 3 phiên bản với tile sau gấp đôi tile trước.

Cũng tại sự kiện thì Intel cũng không ngại tiết lộ thành phần nào được hãng tự sản xuất và thành phần nào thuê gia công. Với dòng Xe-LP, GPU được trang bị trên Tiger Lake, cho card đồ họa DG1 tầm trung và SG1 cho máy chủ thì chúng đều được sản xuất trên tiến trình 10nm SuperFin. Riêng Xe-HPG thì đây là dòng GPU duy nhất được sản xuất bởi một đối tác thứ 3, khả năng là TSMC nhưng Intel cũng có thể thuê thêm hãng khác như Samsung. Riêng dòng Xe-HPC với tên mã Ponte Vecchio thì Intel liệt kê cụ thể hơn. Phần base sẽ dùng tiến trình 10nm SuperFin, phần nhân tính toán dùng tiến trình tiếp theo của Intel và external tức thuê tiến trình ngoài, phần bộ đệm Rambo cache sẽ dùng tiến trình 10nm Enhanced SuperFin tức cải tiến từ 10nm SuperFin hiện tại và riêng phần Xe Link (cầu liên kết giữa các GPU) và khối xử lý I/O sẽ thuê sản xuất.
Xem chi tiết bài viết:
Intel ra mắt Core i thế hệ 11 tích hợp nhân đồ họa Iris Xe
4 bước cơ bản để tô màu xen kẽ trong Excel
Tại sao cần format USB ? Format USB như thế nào ?
khóa học photoshop tại quận bình tân, quận 6, quận 11, tân tạo, vĩnh lộc, tân phú, khóa học thiết kế đồ họa corel, photoshop, adobe illustrator ai tại bình chánh, hưng long, an phú tây, long thượng, tân quý tây, cầu tràm, gò đen, qui đức, tân kim, cần giuộc, long hậu, mỹ lộc, long trạch, phước hậu, long khê, phước lợi, long định, phước vân, long cang, thuận thành, trường bình, nhơn đức, long thới, bình điền, quận 7, phú mỹ hưng, phú lợi, phước lộc, rạch kiến, tiền giang, cần thơ, word, excel, vi tính văn phòng, học tin học cấp tốc, khóa học vi tính ngắn hạn, dạy photoshop corel cấp tốc tại long an, phước lý, tiền giang, cần thơ, dạy word excel tại đinh đức thiện, dạy photoshop cấp tốc, superfin